Die Semantic Web Initiative
Die Semantic Web Initiative
Treibende Kraft hinter dem Semantic Web ist das World Wide Web Consortium, dass es sich zur Aufgabe gemacht hat, Standards für das bestehende Web und für die Weiterentwicklung des Web zu entwickeln. „W3C’s mission is: To lead the World Wide Web to its full potential by developing protocols and guidelines that ensure long-term growth for the Web.”1 Über den aktuellen Stand und die aktuellen Vorhaben sowie die bestehenden Spezifikationen zum Semantic Web kann man sich auf der „W3C Semantic Web Activity Seite“ informieren. Dort findet sich auch der Semantic Web Layer Cake (siehe unten), der die bereits entwickelten Standards zeigt, die die Basis des Semantic Web bilden.
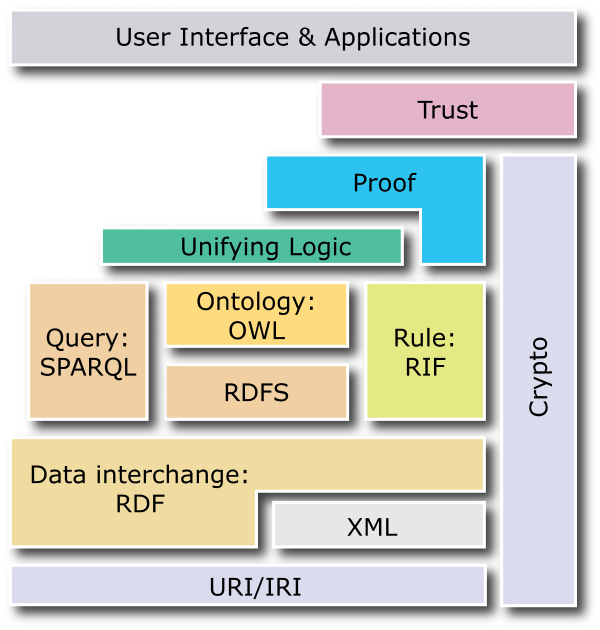 Semantic Web Layer Cake (W3C)
Semantic Web Layer Cake (W3C)
Die unterste Ebene des Layer Cake bildet das Konzept der Universal Resource Identifier (URI) oder Internationalized Resource Identifier (IRI). Es gewährleistet, dass im Web weltweit eindeutige „Namen” für Ressourcen vergeben werden können. Information als Ressource betrachtet, kann somit eindeutig adressiert werden und folglich auch immer wiederverwendet werden. Dieses Prinzip löst Information aus einem zweidimensionalen, hierarchischen Denken wie in einem Ordnersystem, in dem Information z.B. unter Kategorie A und dann vielleicht noch Kategorie B abgelegt wird und im schlimmsten Fall dabei auch noch dupliziert wird, wodurch nicht mehr gewährleistet werden kann, dass die Information, die man in Kategorie A findet der entspricht, die man in Kategorie B findet. Wenn Information eindeutig adressiert werden kann, kann sie über diese Adresse auch in jeden (hoffentlich sinnvollen) Kontext eingebunden oder vernetzt werden. Vor allem aber existiert sie nur einmal und wenn sie an einer Stelle geändert wird, dann ist diese Änderung in allen Fällen wo sie eingebunden ist, wirksam.
Die unterste Ebene des Layer-Cake bildet das Konzept der Universal Ressource Identifier (URI) oder Internationalized Ressource Identifier (IRI). Es gewährleistet, dass im Web weltweit eindeutige "Namen" für Ressourcen vergeben werden können. Information als Ressource betrachtet, kann somit eindeutig adressiert werden und somit auch immer wiederverwendet werden. Dieses Prinzip löst Information aus einem zweidimensionalen, hierarchischen Denken, wie in einem Ordnersystem, in dem Information z.B. unter Kategorie A und dann vielleicht noch Kategorie B abgelegt wird und im schlimmsten Fall dabei auch noch dupliziert wird, wodurch nicht mehr gewährleistet werden kann, dass die Information die man in Kategorie A findet der entspricht die man in Kategorie B findet. Wenn Information eindeutig adressiert werden kann, kann Sie über diese Adresse auch in jeden (hoffentlich sinnvollen) Kontext eingebunden oder vernetzt werden und vor allem sie existiert nur einmal und wenn sie an dieser Stelle geändert wird, dann ist diese Änderung auf in allen Fällen wo sie eingebunden ist wirksam.
In order to communicate internally, a community agrees (to a reasonable extent) on a set of terms and their meanings. One goal of the Web, since its inception, has been to build a global community in which any party can share information with any other party. To achieve this goal, the Web makes use of a single global identification system: the URI. URIs are a cornerstone of Web architecture, providing identification that is common across the Web. The global scope of URIs promotes large-scale “network effects”: the value of an identifier increases the more it is used consistently.2
Die zweite Ebene des Layer Cake hat als Grundlage die Extensible Markup Language (XML), die es ermöglicht, Information strukturiert darzustellen und zusätzlich die Struktur bei Bedarf zu erweitern bzw. eigene Strukturen (Vokabulare) zu definieren. Durch den Austausch bzw. die Verknüpfung der Vokabulare kann auch die Information austauschbar gemacht bzw. verknüpft werden. Das Resource Description Framework (RDF) ist ein XML-Vokabular, das nicht dazu entwickelt wurde, um die Information selbst zu strukturieren, sondern um Information über die Information selbst zu generieren, zu verknüpfen und austauschbar zu machen. Information wird dabei als Ressourcen gesehen, die über URIs adressiert wird.3
The Resource Description Framework (RDF) is a language for representing information about resources in the World Wide Web. It is particularly intended for representing metadata about Web resources, such as the title, author, and modification date of a Web page, copyright and licensing information about a Web document, or the availability schedule for some shared resource. However, by generalizing the concept of a “Web resource”, RDF can also be used to represent information about things that can be identified on the Web, even when they cannot be directly retrieved on the Web. Examples include information about items available from on-line shopping facilities (e.g., information about specifications, prices, and availability), or the description of a Web user’s preferences for information delivery.4
Die dritte Ebene liefert mit RDF-Schema (RDFS) und der Web Ontology Language (OWL) Erweiterungen für RDF. Diese bieten die Möglichkeit, Taxonomien und Ontologien und damit komplexe Wissensrepräsentationen aufzubauen. Zusätzlich steht mit SPARQL (SPARQL Protocol and RDF Query Language) eine Abfragesprache für RDF zur Verfügung, mit der wie in einer Datenbank Abfragen für semantisch ausgezeichneten Daten generiert werden können. Wie man sieht, bauen alle diese Standards aufeinander auf bzw. bedingen einander. Wobei aber auch festzustellen ist, dass die weiteren Ebenen („Proof“ und „Trust“) nur angedeutet sind, da für sie noch keine Konzepte und Standards entwickelt wurden. Sie erscheinen dennoch zentral für die Entwicklung und vor allem für den breiten Einsatz des Semantic Web zu sein. Denn gerade Konzepte für „Proof” und „Trust”, d.h. dafür, dass gewährleistet ist, dass die Information korrekt ist und man ihr „vertrauen” kann, sind eine grundlegende Voraussetzung für die Entwicklung des Semantic Web. Das Fehlen dieser Konzepte weist allerdings auch schon darauf hin, wie schwierig es ist, diese Themen zu formalisieren und in Standards zu fassen.
Wie wichtig dieses Thema ist, zeigt wohl auch die Keynote von Tim Berners-Lee anlässlich der World Wide Web Conference 20095 in Madrid zum Thema „Twenty Years: Looking Forward, Looking Back”. Darin fordert er ein sauberes Internet, in dem die Benutzer wissen, welchen Daten sie vertrauen können und in dem die Herkunft von Daten zurückverfolgt werden kann.6
- ^ Jacobs 2008, Stand 4.5.09
- ^ Berners-Lee 2004b, Stand 15.4.2009
- ^ Birkenbihl 2006, S. 80
- ^ (Manola 2004, Stand 15.4.2009
- ^ World Wide Web Conference 2009
- ^ orf.at, Stand 22.4.2009